Off-chain operations
While Walrus operations happen off Sui, they might interact with the blockchain flows defining the resource life cycle.
Write paths
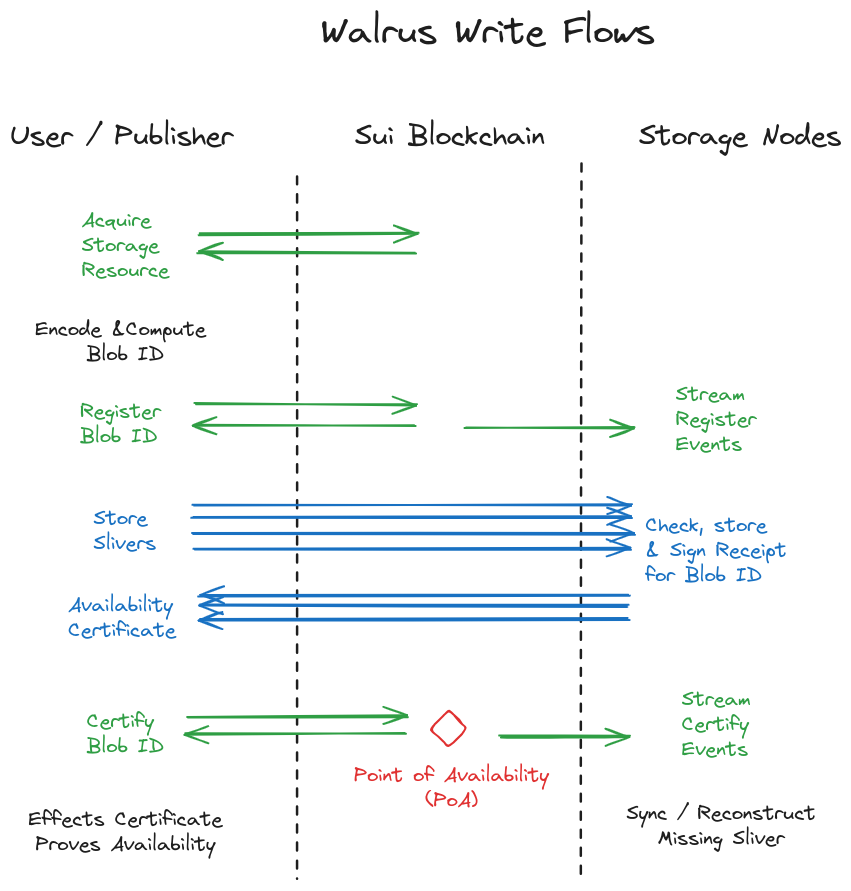
Systems overview of writes, illustrated in the previous image:
-
A user acquires a storage resource of appropriate size and duration on chain, either by directly buying it on the Walrus system object or a secondary market. A user can split, merge, and transfer owned storage resources.
-
When users want to store a blob, they first erasure code it and compute the blob ID. Then they can perform the following steps themselves, or use a publisher to perform steps on their behalf.
-
The user goes on chain (Sui) and updates a storage resource to register the blob ID with the desired size and lifetime. This emits an event, received by storage nodes. After the user receives they then continue the upload.
-
The user sends the blob metadata to all storage nodes and each of the blob slivers to the storage node that currently manages the corresponding shard.
-
A storage node managing a shard receives a sliver and checks it against the blob ID. It also checks that there is a blob resource with the blob ID that is authorized to store a blob. If correct, the storage node then signs a statement that it holds the sliver for blob ID (and metadata) and returns it to the user.
-
The user puts together the signatures returned from storage nodes into an availability certificate and submits it to the chain. When the certificate is verified on chain, an availability event for the blob ID is emitted, and all other storage nodes seek to download any missing shards for the blob ID. This event emitted by Sui is the point of availability (PoA) for the blob ID.
-
After the PoA, and without user involvement, storage nodes sync and recover any missing metadata and slivers.
The user waits for 2/3 of shard signatures to return to create the certificate of availability. The rate of the code is below 1/3, allowing for reconstruction even if only 1/3 of shards return the sliver for a read. Because at most 1/3 of the storage nodes can fail, this ensures reconstruction if a reader requests slivers from all storage nodes. The full process can be mediated by a publisher that receives a blob and drives the process to completion.
Refresh availability
Because no content data is required to refresh the duration of storage, refresh is conducted fully on chain within the protocol. To request an extension to the availability of a blob, a user provides an appropriate storage resource. Upon success this emits an event that storage nodes receive to extend the time for which each sliver is stored.
Inconsistent resource flow
When a correct storage node tries to reconstruct a sliver for a blob past PoA, this may fail if the encoding of the blob was incorrect. In this case, the storage node can instead extract an inconsistency proof for the blob ID. It then uses the proof to create an inconsistency certificate and upload it on chain.
The flow is as follows:
-
A storage node fails to reconstruct a sliver, and instead computes an inconsistency proof.
-
The storage node sends the blob ID and inconsistency proof to all storage nodes of the Walrus epoch. The storage nodes verify the proof and sign it.
-
The storage node who found the inconsistency aggregates the signatures into an inconsistency certificate and sends it to the Walrus smart contract, which verifies it and emits an inconsistent resource event.
-
Upon receiving an inconsistent resource event, correct storage nodes delete sliver data for the blob ID and record in the metadata to return
Nonefor the blob ID for the availability period. No storage attestation challenges are issued for this blob ID.
A blob ID that is inconsistent always resolves to None upon reading because
the read process re-encodes the received blob to check that the blob ID is correctly derived from a
consistent encoding. This means that an inconsistency proof reveals only a true fact to storage
nodes (that do not otherwise run decoding), and does not change the output of read in any case.
However, partial reads leveraging the systematic nature of the encoding might successfully return partial reads for inconsistently encoded files. Thus, if consistency and availability of reads is important, dApps should do full reads rather than partial reads.
Read paths
A user can read stored blobs either directly or through an aggregator/cache. The operations are the same for direct user access, for aggregators, and caches in case of cache misses. In practice, most reads happen through caches for blobs that are hot and do not result in requests to storage nodes.
-
The reader gets the metadata for the blob ID from any storage node, and authenticates it using the blob ID.
-
The reader then sends a request to the storage nodes for the shards corresponding to the blob ID and waits for to respond. Sufficient requests are sent in parallel to ensure low latency for reads.
-
The reader authenticates the slivers returned with the blob ID, reconstructs the blob, and decides whether the contents are a valid blob or inconsistent.
-
Optionally, for a cache, the result is cached and can be served without reconstruction until it is evicted from the cache. Requests for the blob to the cache return the blob contents, or a proof that the blob is inconsistently encoded.
Challenge mechanism for storage attestation
During an epoch, a correct storage node challenges all shards to provide symbols for blob slivers past PoA:
-
The list of available blobs for the epoch is determined by the sequence of Sui events up to the past epoch. Inconsistent blobs are not challenged, and a record proving this status can be returned instead.
-
A challenge sequence is determined by providing a seed to the challenged shard. The sequence is then computed based both on the seed and the content of each challenged blob ID. This creates a sequential read dependency.
-
The response to the challenge provides the sequence of shard contents for the blob IDs in a timely manner.
-
The challenger node uses thresholds to determine whether the challenge was passed, and reports the result on chain.
-
The challenge/response communication is authenticated.
Challenges provide some reassurance that the storage node can actually recover shard data in a probabilistic manner, avoiding storage nodes getting payment without any evidence they might retrieve shard data. The sequential nature of the challenge and some reasonable timeout also ensures that the process is timely.